普通のWebページの文を"読めてしまう"文に変換するRubyスクリプト
今朝読んでおもしろかった話題。
http://www.asks.jp/users/hiro/59059.html
http://www.itmedia.co.jp/news/articles/0905/08/news021.html
確かに読める!
しかし上のページで取り上げられているのはたまたま読みやすかっただけで、一般的にはそうじゃないかもしれない。
そこで任意のWebページの文を、上のような"読めてしまう"文に変換するためのスクリプトを書いた。
reading_trivia.rb
$KCODE ='u' require 'rubygems' require 'hpricot' require 'open-uri' require 'cgi' require 'kconv' require 'extractcontent' def reading_trivia(url) #extractcontentで本文を抽出 html = '' open(url) {|f| html = f.read.toutf8} body, title = ExtractContent::Extractor.new.analyse(html) #Yahoo!日本語形態素解析APIで各形態素の読み仮名を求める app_id = 'yahoo_app_id' #自分のYahoo!アプリケーションID doc = open("http://jlp.yahooapis.jp/MAService/V1/parse?appid=#{app_id}&results=ma&response=reading&sentence=#{CGI.escape(body)}") {|f| Hpricot(f)} words = (doc/:reading).map {|i| i.inner_text} #4文字以上の単語の場合に、単語の両端以外の文字をシャッフルする sentence = [] words.each do |word| c = word.split(//) if c.size > 3 sentence << c[0] + c[1..-2].sort_by{rand}.join + c[-1] else sentence << word end end puts sentence.join(' ') end if __FILE__ == $0 reading_trivia(ARGV.shift) end
日本語形態素解析には前回と同様にYahoo!日本語形態素解析APIを使った。
http://developer.yahoo.co.jp/webapi/jlp/ma/v1/parse.html
また本文抽出にはextractcontentというRubyモジュールを使った。
http://labs.cybozu.co.jp/blog/nakatani/2007/09/web_1.html
extractcontentのインストールは
% sudo gem install extractcontent
とかでOK.
(Hpricotが入っていない場合もgem install hpricotで。gemすら入ってない場合は"gem インストール"とかでググればOK)
引数にはWebページのURLを指定する。
例えば昨日の任天堂に関する記事でやってみるとこんな感じ。
http://japan.cnet.com/news/biz/story/0,2000056020,20392731,00.htm
% ruby reading_trivia.rb http://japan.cnet.com/news/biz/story/0,2000056020,20392731,00.htm > hoge.txt % cat hoge.txt
にてんんどう 、 うだりあげか 、 りえき ともに かこ さいこう -- かがいい うありげ ひりつ は 87.5 % に
ながい みちこ ( へんしゅう ぶ )
2009 / 05 / 07 18 : 33
にんんてどう は 5 がつ 7 にち 、 2009 ねん 3 がつ き の つうき れんけつ けっさん を はぴっょう し た 。 うだげりあか 、 えいぎょう りえき 、 けょじいう りえき 、 じんえゅりき ともに かこ さこいう を きろく し た 。 かがいい うりあげ ひりつ は 87.5 % に のぼる 。
うげりあだか は ぜきんひ 9.9 % ぞう の 1 ちょう 8386 おく えん 、 えぎいょう りえき は どう 1.40 % ぞう の 5552 おく えん 、 けょじいう りえき は どう 1.8 % ぞう の 4846 おく えん 、 じりえんゅき は どう 8.5 % ぞう の 2970 おく えん と なっ た 。 なお 、 えだんか の えょいきう で 、 かわせ さそん を 1339 おく えん けいょじう し て いる 。 うりだげあか の 87.5 % に あたる 1 ちょう 6906 おく えん は かいがい で の うりあげ だ 。
けたいい がた げーむき 「 にんてどんー DS Lite 」 の うありげ が かいがい で こちょうう だっ た ほか 、 2008 ねん 11 がつ 1 にち に 「 にどんんてー DSi 」 を こくない むけ に はばつい し た こと で 、 にどんてんー DS しりーず の ぜん せかい はんばい だいすう は とうき で 3118 まん だい 、 るけいい で 1 おく 178 まん だい と なっ た 。 「 げーむき と し て は しじょう さいたん の きかん で 1 おく だい を こえ た 」 ( にてどんんう ) 。 たいおう そふと と し て は 、 「 ぽけすたもんとっー ぷらちな 」 が 375 まん ほん 、 「 ほし の かー ヴぃ うるとら すぱーー でらくっす 」 が 236 まん ほん 、 「 のう を きえたる おとな の DS とにれんーぐ 」 「 もっと のう を きたえる おとな の DS とんれーにぐ 」 が 2 さく ごけうい で 731 まん ほん はばんい さ れ た 。
すえおき がた げむーき 「 Wii 」 に つい て は 、 かいがい で の はんばい が こうちょう だっ た と いう 。 ぜん せかい の はんばい だいすう は とうき で 2955 まん だい 、 るいけい で 5309 まん だい と なり 、 「 もとっも はやく るけいい はばんい だいすう が 5000 まん だい を とっぱ し た げーむき に なっ た 」 ( にんてどんう ) と の こと 。 たいおう そふと で は 「 まりかおーと Wii 」 が 1540 まん ほん 、 「 まち へ いこ う よ どうつもぶのり 」 が 338 まん ほん 、 「 Wii Msuic 」 が 265 まん ほん うれ た 。 さらに 「 Wii Fit 」 が かいがい でも ひっと し 、 1367 まん ほん はんばい し て いる 。
2010 ねん 3 がつ き に つい て は 、 にどんんてー DSi を かがいい でも はつばい する ほか 、 しんはもき に 「 ぜでんのせだるつ すりっぴと とくらっす ( かょしう ) 」 を はつばい する 。 さらに 、 りある な すーぽつ たいけん を ていょきう する 「 Wii すーぽつ りぞーと 」 も ぜん せかい で てんかい する けいかく 。 ただし 、 うあだげりか は 1 ちょう 8000 おく えん 、 えょいぎう りえき は 4090 おく えん 、 けいじょう りえき は 5000 おく えん 、 じゅえんりき は 3000 おく えん と よばこい を みこん で いる 。
たしかに読めるけれども、あまりなじみのない単語が多いせいか可読性は最初に見た例よりは落ちている気がする。
あと形態素解析器を使うと人手でわかち書きするよりも細かく分けてしまう場合が多いので、3文字以下の単語が増えている。
脳内でどんな処理が行われているのかわからないけど、不思議。
特に関連していないかもしれない記事:
ひらがなせいかつ への いざない - ぼんやりと考えたこと
http://n.h7a.org/blog/entry/1594
P.S.
書き終えた後にdankogaiさんがJavaScriptで似たようなことをすでにやっていたことに気づいた...
http://blog.livedoor.jp/dankogai/archives/51210157.html
Twitterの投稿内容から鬱度を測定する
もうすぐ5月です。
Twitterの投稿内容から鬱度を測定するRubyスクリプトを書いてみました。
これには東京工業大学の高村さんが公開している単語感情極性対応表というものを使っています。
http://www.lr.pi.titech.ac.jp/~takamura/pndic_ja.html
これはある単語がどの程度の感情を表すかを数値化した表で、-1 ~ +1 までの値が特定の単語に割り当てられています。
その単語がネガティブな感情表現だとマイナスの値、ポジティブな感情表現だとプラスの値になっています。
なので、鬱度を測定といってもポジティブな投稿内容が多いときにはプラスの値を返します。
また日本語文の形態素解析にはYahoo!の日本語形態素解析APIを使っています。
http://developer.yahoo.co.jp/webapi/jlp/ma/v1/parse.html
アプリケーションIDさえ取得すれば、新たにソフトもインストールする必要がないので気軽に使えます。
$KCODE = 'u' require 'rubygems' require 'hpricot' require 'open-uri' require 'cgi' require 'kconv' def utsu_score pn_ja = [] open('http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic') {|f| while l = f.gets pn_ja << l.chomp.toutf8.split(':') end } app_id = 'yahoo_app_id' #Yahoo!のアプリケーションIDを入力 statuses = twitter_statuses('user_name') #調べたいユーザーのユーザー名を入力 total_score = 0 statuses.each do |status| doc = open("http://jlp.yahooapis.jp/MAService/V1/parse?appid=#{app_id}&results=ma&response=baseform&sentence=#{CGI.escape(status)}") {|f| Hpricot(f)} words = (doc/:baseform).map {|i| i.inner_text} score = 0 words.each do |w| if i = pn_ja.assoc(w) score += i[3].to_f end end total_score += score end p (total_score / 20) ** 3 end def twitter_statuses(user_name) doc = open("http://twitter.com/statuses/user_timeline/#{user_name}.xml") {|f| Hpricot(f)} (doc/:text).map {|i| i.inner_text} end if __FILE__ == $0 utsu_score end
ログイン作業などは書いていないので、パブリックなユーザーのみ測定できます。
単語感情極性対応表を用いて直近20個の投稿について平均スコアを出し、それを3乗しています。
たぶん、ふつうの内容であれば±10前後のスコアだと思います。
少し使ってみた感じだとプラスの値が出るのは結構まれで、たいていの場合マイナスになるようです。
もし-10以下であるようだったら、ちょっとネガティブな発言が近頃多いのかもなー、ぐらいに思っておけばいいんじゃないでしょうか。
逆に+10以上であれば相当ポジティブであると自信を持って良いと思います。
yazztter(yet another buzztter)をつくりました
Twitterにおいて、今ホットなキーワードをおしえてくれるボット、yazztterを作りました。
http://twitter.com/yazztter
背景
前からこんなのをちょっと作ってみたかったのというのと、ちょうどチームラボのアルゴリズムコンテストというものが開かれていたので、ちょうど良いタイミングだと思い、作ってみました。
http://www.team-lab.com/news/index.php?itemid=469
中身
同様のボットとしてbuzztter(http://twitter.com/buzztter)がありますが、ホットなキーワードを導出するための方法が異なっています。
yazztterでは、東京工業大学の藤木さんたちが提案した以下の手法の一部を用いています。
http://www.lr.pi.titech.ac.jp/blogwatcher/paper/NL-160-13.pdf
これはKleinbergの提案したburst検出手法を拡張したもので、各documentの出現間隔に着目した手法です。
Twitterにおいては、頻繁に出現する単語とそうでない単語がありますが、それらが日常的に出現する間隔を考慮して、日常より頻繁に出てくるようであればより大きなスコアを与える、というようなことを行っています。
実装がまだ雑なので、期待通りの結果を出してくれないことがままありますが大目に見てください。
最後に
Twitterのデータ(日本語のPublic Timeline)は@penguinanaさんのtwitter検索を利用しています。ありがとうございます。
http://pcod.no-ip.org/yats/public_timeline
またid:darashiさんによるbuzztterの解説はとても参考になりました。
http://d.hatena.ne.jp/darashi/20071106/1194365071
アイコン画像は以下のページのものを使用させていただきました。
http://sky.geocities.jp/hoopmasa137/page005.html
N・ひろしまさんとの昼食 at Google Japan

http://flickr.com/photos/gyazickr/3326835961
ひろしまさん(http://n.h7a.org/blog/)が来日中*1とのことで、Googleの日本オフィスでお会いすることに。
ランチタイムに伺ったところ、その日は寿司の日らしく、写真の寿司セットを食べることができた。しかもこの寿司セットは(たぶん)食べ放題でおかわりしようと思えばいくらでもできたようであったし、飲み物も相変わらず自販機のボタンを押すだけで出てくるし、最近Googleの福利厚生が(ry という話は食堂からは微塵も感じられなかった。
ひろしまさん、ありがとうございました。
ひろしまさんはシリコンバレー力*2が最も高い日本人の1人で、JTPAのスタッフ(今はCo-president)でもある(http://www.jtpa.org/staff/)。
僕が参加したシリコンバレーツアーのときも、「起業家セッション」でスピーカーとして登場し、変わった人たちが集まっているその中でも独特の雰囲気を放っていた。そのあまりの雰囲気に、初めて話した千賀さんの出版記念パーティーのときに「アカギに似ていると言われたことありませんか?」と、若干意味不明なことを質問してしまったほどw
最終日の夜には翌朝の6, 7時ぐらいまで、アメリカでのいろんなおもしろい話などを聞いたりして、とてもエキサイティングだった。
それはともかくとして、今回のシリコンバレーカンファレンスではひろしまさんがマウンテンビューのGoogleplexを案内してくれるらしいので、お金と時間に少しでも余裕があるひとは今からでも申し込んでみるのはいかがでしょうか。
面白すぎる話にぜひ期待してください。
カンファレンスの締切は過ぎてしまっているけど、参加権譲渡なども行われているらしいので、まだいけるはず!
http://www.chikawatanabe.com/blog/2009/02/jtpaconference.html
カンファレンス当日のプログラムも発表されているのだけれど、去年まで数日に渡って行われていたセッションを一日に凝縮した感じになっていて、日本から行く人にとっては集合を含め、相当なハードプログラムになっている模様w
http://www.jtpa.org/event/svtour/000490.html
シリコンバレーカンファレンス参加者の皆さんは思う存分楽しんできてください!
NLP(自然言語処理)研究者をスコアリングしてみた
IR研究者をスコアリングしてみた - 睡眠不足?!
http://d.hatena.ne.jp/sleepy_yoshi/20090215/p1
この記事を読んでNLP分野ではどうだろう、と思ったのでやってみました。
対象とした会議は2001年~2008年のACLとEMNLPです(年によっては他会議との併設含む)。
cf. DO++: 自然言語処理の学会 http://hillbig.cocolog-nifty.com/do/2008/04/post_fe44.html
ACL anthologyから以下のページを利用してデータを取得
ACL: http://www.aclweb.org/anthology-new/P/P08/ (2008年の場合。08の部分を変えれば他の年が見られる)
EMNLP: http://www.aclweb.org/anthology-new/sigdat.html
評価方法
冒頭のIR研究者のスコアリングの場合と同様で、登場回数と著者順位による重みづけによる二つの方法を用いました。
「登場回数は名前が出れば1回とカウント」、「著者順位重みづけは1st authorの重要度をそれ以外の著者よりも重くしてスコアづけ」(複数人の著者がいる場合は1st authorを0.8として、残りの0.2を他の著者に分配、1人の場合は1とする)です。
また、Short PaperやPoster, Workshopなどは対象外としました。
コード
書いたコードは下の通り。名前の表記揺れがいくつかあったので「大文字」+.(ピリオド)は除去してカウントしたりして(例: "Christopher D. Manning" => "Christopher Manning")、最後に手作業で補完しました。
$KCODE = 'u' require 'rubygems' require 'nokogiri' require 'open-uri' #ACLの論文著者名を取得 def acl_authours authors = [] (1 .. 8).each do |y| doc = Nokogiri::HTML(open("http://www.aclweb.org/anthology-new/P/P0#{y}/")) (doc/'p').each do |i| num = (i/'a').first.inner_text.scan(/\d{4}$/).to_s.to_i if num > 1000 && num < 2000 next if (i/'b').inner_text.split(//).size < 1 authors << (i/'b').inner_text.gsub(/(\.)[^ ]/) {$1 + ' '}.gsub('’', "'").gsub(/\(.+?\) /, '').gsub(/ {2,}/, ' ').gsub(/[A-Z]\. /, '').split('; ') end end sleep 3 end authors end #EMNLPの論文著者名を取得 def emnlp_authors authors = [] doc = Nokogiri::HTML(open("http://www.aclweb.org/anthology-new/sigdat.html")) (doc/'li').each do |i| num = (i/'a').first.inner_text.scan(/(\d+)-/).to_s.to_i if num >= 1 && num <= 8 next if (i/'b').inner_text.split(//).size < 1 authors << (i/'b').inner_text.gsub(/([a-z]{2,}|\.)([A-Z])/) {$1 + ' ' + $2}.gsub('’', "'").gsub(/ {2,}/, ' ').gsub(/[A-Z]\. /, '').split('; ') end end authors end #フラットな配列を引数に取りカウント def count_authors(authors) cnt = Hash.new(0) authors.each do |i| cnt[i] += 1 end cnt.to_a.sort {|a, b| b[1] <=> a[1]} end #配列の配列を引数に取りスコアを分配 FIRST_AUTHOR_SCORE = 0.8 def devide_score(authors) score = Hash.new(0) authors.each do |i| if i.size == 1 score[i.shift] += 1 else score[i.shift] += FIRST_AUTHOR_SCORE rest_score = (1 - FIRST_AUTHOR_SCORE) / i.size i.size.times do |t| score[i.shift] += rest_score end end end score.to_a.sort {|a, b| b[1] <=> a[1]} end if __FILE__ == $0 p count_authors((acl_authours + emnlp_authors).flatten) p devide_score((acl_authours + emnlp_authors)) end
結果
登場回数順(10回以上)
スコア順(有効数字4桁, 4.000以上)
最後に
URLは適当なものではない可能性があります。
Christopher D. Manning先生が書かれた教科書は輪講などでも広く使われています。
http://nlp.stanford.edu/fsnlp/
Dan Klein先生の担当されている授業の資料などは誰でも見ることができます。
http://www.cs.berkeley.edu/~klein/cs288/sp09/
がんばります。
はてなブックマークの被お気に入り登録数を調べてみた

以前に同様のことをやっていた方がいたようですが、もう一年近く更新されていないようなので改めて調べてみました。
http://b.hatena.ne.jp/entry/849289
http://d.hatena.ne.jp/jt_noSke/20070628
http://d.hatena.ne.jp/jt_noSke/20070801
調査期間や対象ユーザー
6/4(水)~6/6(金)ぐらいに、前回までの調査結果に載っていたユーザーおよび4月, 5月のhotenryに入った記事にブックマークしていたユーザーを対象としました。
対象ブックマーカー数は16767でした。(すでにアカウントが無くなっていたユーザなど含む)
結果など
得られた結果をグラフにしてみたのが冒頭の図です。
縦軸が被お気に入り登録数で、横軸にブックマーカーを被お気に入り登録数が多い順に並べています。
まさにいわゆるロングテールで、最近読んだ「新ネットワーク思考」に書いてあったスケールフリーネットワークをここでも確認することができ、興味深いです。

新ネットワーク思考―世界のしくみを読み解く
posted with amazlet at 08.06.10

 課長
課長  ネットワークとは
ネットワークとは ネットワークから
ネットワークから被お気に入り登録数が多いブックマーカー上位300人は下の表のようになりました。
















































































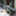

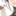
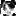


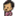






























































































































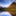














やはり前回と比べると全体的に被お気に入り登録数は増えています。
前回まであった大旦那とかの区分けは面倒だったのでやってないです。
上のような人でhotenryのようなものを再構成してみたらおもしろいんじゃないかとも思いましたが、すでにやっている方がいました。
http://d.hatena.ne.jp/aki77/20070813
今はサービスが止まっているようですが、あんまりそういうニーズはなかったんですかね。
単純に1ブックマーカーにつき1ブックマーク数というのではなく、被お気に入り登録数に応じて重み付けをして、1000ポイントとかポイントで表示するようにしてもおもしろいかも。
ここに載せられなかった残りのデータなど、欲しい方がいらっしゃいましたらメールなどで送るので言ってください。
YAPC::Asia 2008が終わって
去年に引き続きボランティアスタッフとしてYAPCに参加させてもらいました。
今回は東工大・大岡山キャンパスで行われ、2日間とも晴天で本当に良かったです。
アンケート結果などでも会場に関する評価は良好なようで、なんだかうれしかったです。
個々のセッションはニコニコ動画にあがっています。
http://www.nicovideo.jp/tag/yapcasia2008
感想などはyapcasia2008タグで。
http://b.hatena.ne.jp/t/yapcasia2008
YAPCの写真(takesako's flickr)
http://flickr.com/photos/takesako/sets/72157605075794701/(1日目)
http://flickr.com/photos/takesako/sets/72157605091703997/(2日目)
僕は普段はRubyを書いていたりするのだけれど、YAPCに参加して思うのは、去年も感じたようにやっぱりPerlコミュニティは素晴らしい、ということ。
本当にみんな楽しそうに話をしていたりコードを書いたりしている。
YAPCというのはプログラミング言語Perlのカンファレンスなわけだけど、Perlをコミュニケーションのための、まさに言語としても使うおもしろい人たちが集まってガヤガヤやっているという表現が個人的にはしっくりくる。
IT業界に興味があります、という学生こそ、よくわからない就活セミナーとか座談会に行くのではなくてYAPCに来てみるべきだと思う。去年の僕がまさしくそんな感じだった。
どうでもいい余談だけど会場のいたるところでMacBookを開いていたid:tokuhiromなどはとてもかっこよかった。
僕もPerlやればかっこよくなれるかもと思って、研究室にあったLearning Perlを読み始めました。
Perlコミュニティといえばid:miyagawaの
「どうやったらPerl Mongersになれますかという人がいたりするけど、ここに来ればもうPerl Mongersです。」
というオープニングスピーチも良かった。これで僕もPerl Mongersです。
また一日目のラリー・ウォールのスピーチで急遽マイク持ちをさせてもらったりもした。とてもいい記念でしたが途中足の感覚がなくなったりしびれたりして、大変でした。

来年はどこでやることになるかわかりませんが、またお手伝いしたいです。
みなさん本当にありがとうございました。
最後にid:TAKESAKOによる感動のYAPCまとめ動画をどうぞ。